Use Red Hat OpenShift's built-in OAuth server as an authentication provider in Open Liberty 20.0.0.1

In Open Liberty 20.0.0.1, you can configure the Social Login feature to use Red Hat OpenShift’s OAuth server for authentication. In addition, there is a new MicroProfile Metric to measure CPU time, memory heap and response time.
In Open Liberty 20.0.0.1:
View the list of fixed bugs in 20.0.0.1.
If you’re interested in what’s coming soon in Open Liberty, take a look at our current development builds. Performance improvements through faster startups with annotation caching, and GraphQL support.
Run your apps using 20.0.0.1
If you’re using Maven, here are the coordinates:
<dependency>
<groupId>io.openliberty</groupId>
<artifactId>openliberty-runtime</artifactId>
<version>20.0.0.1</version>
<type>zip</type>
</dependency>Or for Gradle:
dependencies {
libertyRuntime group: 'io.openliberty', name: 'openliberty-runtime', version: '[20.0.0.1,)'
}Or if you’re using Docker:
FROM open-libertyOr take a look at our Downloads page.

Using Liberty Social Login with Red Hat OpenShift
The Social Login feature socialLogin-1.0 can now be configured to use OpenShift’s built-in OAuth server and OAuth Proxy sidecar as authentication providers. The Social Login feature has several pre-configured providers (e.g. Google, GitHub, Facebook) but you can also configure additional providers (e.g. Instagram). OpenShift’s OAuth server and OAuth Proxy sidecar can now be configured as additional providers too. The first is a standard OAuth Authorization Code flow, where a web browser accessing an app running in Liberty is redirected to the OpenShift OAuth server to authenticate.
The second is accepting an inbound token from the OpenShift OAuth Proxy sidecar or obtained from an OpenShift API call. This approach requires less cluster-specific configuration.
Most users of this will run Liberty in a pod; however, in the Authorization Code flow, Liberty can run outside the OpenShift cluster. In either mode, an optional JWT can be created for propagation to downstream services.
Using OpenShift as a provider differs slightly from other OAuth providers, it requires a service account token to obtain information about the OAuth tokens. Once the: client ID, secret, and token have been obtained from OpenShift, Liberty can be configured as shown below.
To enable the feature add it to the server.xml
Server configuration to use OpenShift OAuth server:
<server description="social">
<!-- Enable features -->
<featureManager>
<feature>appSecurity-3.0</feature>
<feature>socialLogin-1.0</feature>
</featureManager>
<logging traceSpecification="com.ibm.ws.security.*=all=enabled" maxFiles="8" maxFileSize="200"/>
<httpEndpoint id="defaultHttpEndpoint" host="*" httpPort="8941" httpsPort="8946" > <tcpOptions soReuseAddr="true" /> </httpEndpoint>
<!-- specify your clientId, clientSecret and userApiToken as liberty variables or environment variables -->
<oauth2Login id="openshiftLogin"
scope="user:full"
clientId="${myclientId}"
clientSecret="${myclientSecret}"
authorizationEndpoint="https://oauth-openshift.apps.papains.os.fyre.ibm.com/oauth/authorize"
tokenEndpoint="https://oauth-openshift.apps.papains.os.fyre.ibm.com/oauth/token"
userNameAttribute="username"
groupNameAttribute="groups"
userApiToken="${serviceAccountToken}"
userApiType="kube"
userApi="https://api.papains.os.fyre.ibm.com:6443/apis/authentication.k8s.io/v1/tokenreviews">
</oauth2Login>
<keyStore id="defaultKeyStore" password="keyspass" />
<!-- more application config would go here -->
</server>In the sidecar scenario, the configuration changes to accept an inbound token from the sidecar. Server configuration to use OAuth proxy sidecar:
<!-- specify your userApiToken as a liberty variable or environment variable -->
<!-- note that no clientId or clientSecret are needed -->
<oauth2Login id="openshiftLogin"
scope="user:full"
userNameAttribute="username"
groupNameAttribute="groups"
userApiToken="${serviceAccountToken}"
userApiType="kube"
accessTokenHeaderName="X-Forwarded-Access-Token"
accessTokenRequired="true"
userApi="https://kubernetes.default.svc/apis/authentication.k8s.io/v1/tokenreviews">
</oauth2Login>Use of HTTPS communication requires that the server either have a key signed by a well-known certificate authority, which Liberty can trust automatically or that the server’s public key be added to the Liberty trust store. OpenShift does not come with CA-signed keys by default, so the Red Hat OpenShift OAuth server’s public key will need to be added. The most convenient way to do this is to specify an environment variable in server.env. That identifies the file containing the public key in PEM format. Liberty will read the file and add the key to its trust store.
# server.env
# OAuth sidecar scenario: causes the Kubernetes default certificate that is pre-installed in pods to be added to Liberty trust store.
cert_defaultKeyStore=/var/run/secrets/kubernetes.io/serviceaccount/ca.crt
# OAuth server scenario: causes the public keys from /tmp/trustedcert.pem (obtained seperetly) to be added to Liberty trust store.
cert_defaultKeyStore=/tmp/trustedcert.pemMonitor the process CPU time (MicroProfile Metrics 2.0)
A new metric, processCpuTime, which returns the CPU time used by the process on which the JVM is running. The MicroProfile Metrics feature provides information monitoring an application, such as CPU time used, memory heap, response time of servlets.
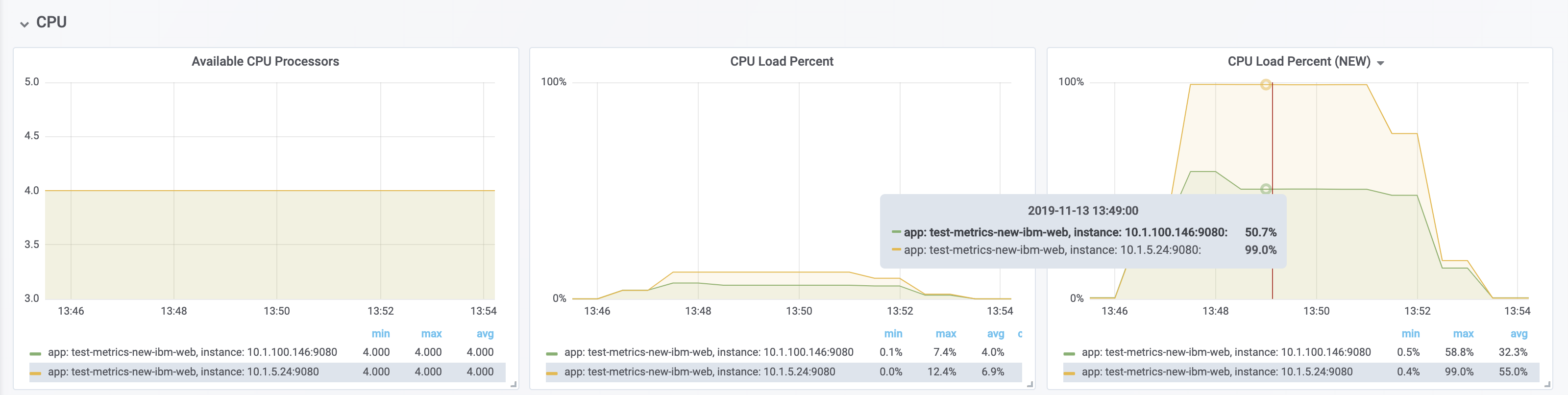
The new processCpuTime metric provides a more accurate CPU load percentage on cloud platforms via Grafana. Previously, the CPU load percentage was shown with the metric processCpuLoad. However, the load percentage was calculated using the total number of cores allocated to the deployment. If the deployment has a restricted number of cores, the processCpuLoad ends up showing a plateau on Grafana when the maximum number of cores is reached. For example, on a deployment with 32 cores allocated but restricted to four cores, the processCpuLoad graph shows a plateau at 12.5% when all four cores are used.
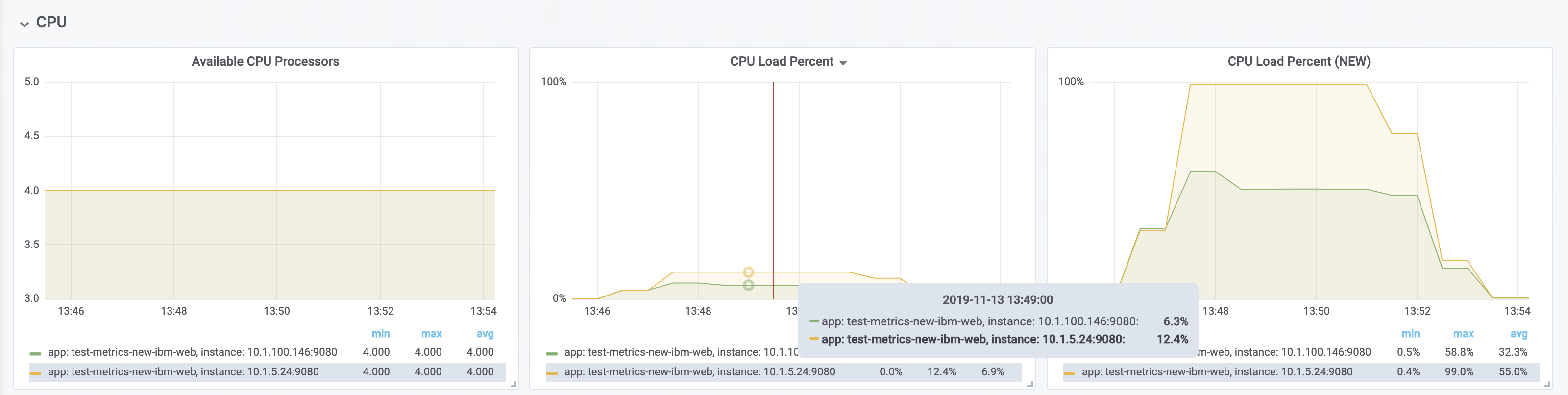
The new metric, processCpuTime, can be manipulated on Grafana to create a more accurate representation of the CPU being used. rate(processCpuTime)[1m] shows the average rate of increase in CPU time over one minute. Dividing this by the total number of CPU cores, we can see a more accurate percentage of the CPU used, taking into account the constraints.
The new processCpuTime metric is displayed on the /metrics endpoint with the MicroProfile Metrics 2.0 and 2.2 features. On the dashboard, a new panel can be created with the following PromQL query: (rate(base:cpu_process_cpu_time[2m])/1e9) / base:cpu_available_processors{app=~}. View full dashboard.
The following images show that the old metric, processCpuLoad, plateaus at 12.5% (4/23), while the new metric, processCpuTime, more accurately represents the percentage of CPU used.
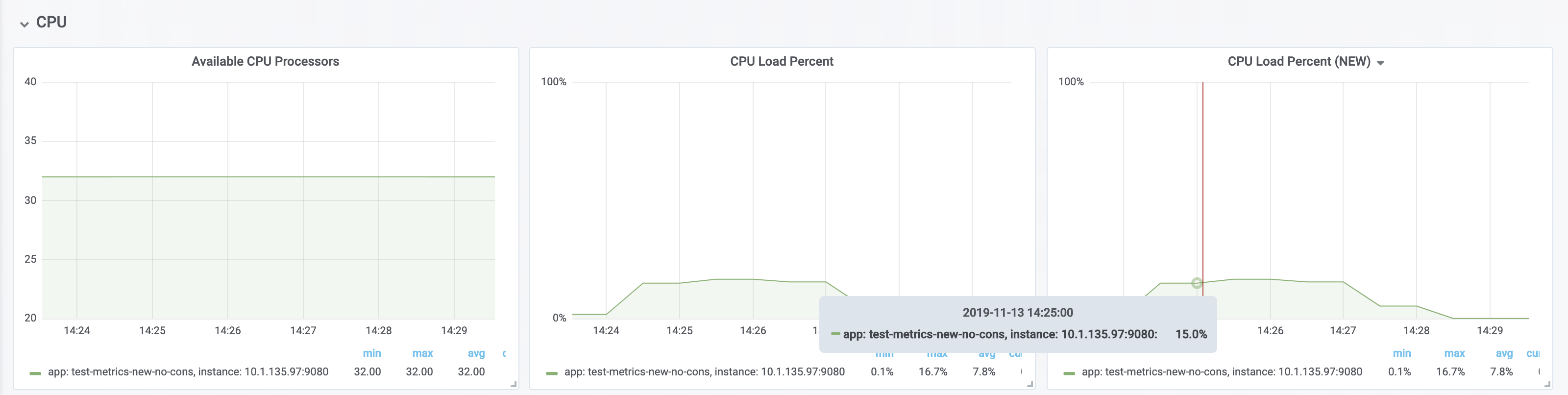
With all the machines cores being used and there are no constraints on the processors (32 processors) - The old version and new version display the same data.
Faster application startups with Liberty annotation caching
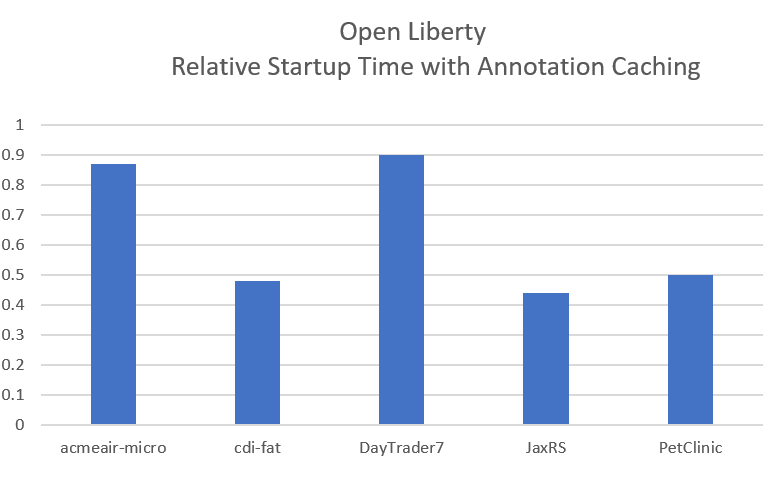
Application startup time is now faster due to adding annotation caching to the core class and annotation scanning function. Depending on application characteristics, startup times are reduced by 10% to more than 50%. Applications with many jar files, or which use CDI or JAX-RS functions, see the best improvements:
Good news! Annotation caching is enabled by default.
Annotation cache data is stored in the server workarea. Cache of application class data is cleared when performing a clean server start (starting the server with the --clean option). In normal operations, the clearing of cache data is not necessary, since the cache automatically regenerates cache data for changed application classes.
In container environments, for annotation caching to be effective, the server image must be "warmed" when the container image is created. Warming the server an be done by starting and stopping the server during the container build. Warming the image moves the annotation scan into the container build meaning you get optimal startup on the container deployment. Using the configure.sh file in the base open-liberty docker images causes the server to be started and stopped during the container build.
Bug fixes in JavaServer Faces 2.3
JavaServer Faces 2.3 contains a new feature to get bug fixes that are in Apache MyFaces 2.3.6. The jsf-2.3 feature pulls in the Apache MyFaces implementation and integrates it into the Liberty runtime.
The Apache MyFaces 2.3.6 release contains bug fixes. View the release notes for more information.
To use the JSF 2.3, enable the jsf-2.3 feature to leverage the latest Apache MyFaces 2.3. release For more information about the JavaServer Feature, view the Apache website.
Previews of early implementations available in development builds
You can now also try out early implementations of some new capabilities in the latest Open Liberty development builds:
These early implementations are not available in 20.0.0.1 but you can try them out in our daily Docker image by running docker pull openliberty/daily. Let us know what you think!
Automatically compress HTTP responses
You can now try out HTTP response compression.
Previous to this feature, Liberty only considered compression through the use of the $WSZIP private header. There was no way for a customer to configure the compression of response messages. Support now mainly consists of using the Accept-Encoding header in conjunction with the Content-Type header, of determining if compression of the response message is possible and supported. It allows the Liberty server to compress response messages when possible. It is beneficial because customers will want to use the compression feature to help reduce network traffic, therefore reducing bandwidth and decreasing the exchange times between clients and Liberty servers.
A new element, <compression>, has been made available within the <httpEndpoint> for a user to be able to opt-in to using the compression support.
The optional types attribute will allow the user to configure a comma-delimited list of content types that should or should not be considered for compression. This list supports the use of the plus “+” and minus “-“ characters, to add or remove content types to and from the default list. Content types contain a type and a subtype separated by a slash “/“ character. A wild card "*" character can be used as the subtype to indicate all subtypes for a specific type.
The default value of the types optional attribute is: text/*, application/javascript.
Configuring the optional serverPreferredAlgorithm attribute, the configured value is verified against the “Accept-Encoding” header values. If the client accepts the configured value, this is set as the compression algorithm to use. If the client does not accept the configured value, or if the configured value is set to ‘none’, the client preferred compression algorithm is chosen by default.
<httpEndpoint id="defaultHttpEndpoint"
httpPort="9080"
httpsPort="9443">
<compression types=“+application/pdf, -text/html” serverPreferredAlgorithm=“gzip”/></httpEndpoint>Open Liberty supports the following compression algorithms: gzip, x-gzip, deflate, zlib, and identity (no compression)
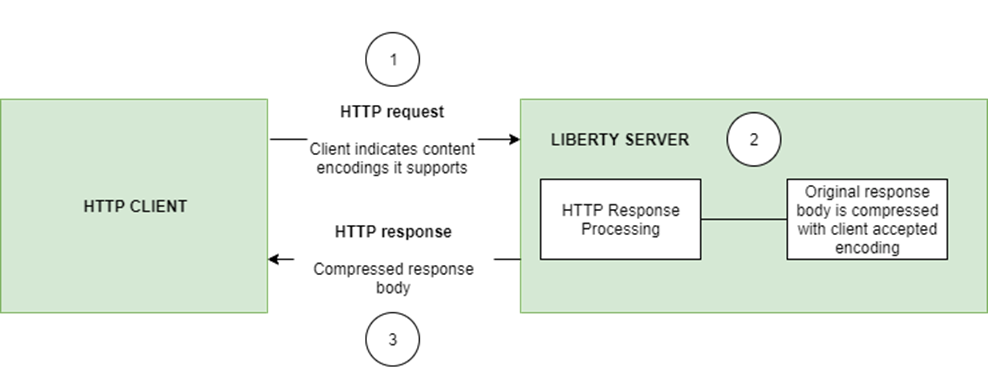
The Http Response Compression functionality has been designed from the following Open Liberty Epic: #7502. The design is outlined within the Epic for more detailed reading. The basic flow of the design is shown in the below diagrams:
You are now free to use GraphQL with Open Liberty!
In our latest OpenLiberty development builds, users can now develop and deploy GraphQL applications. GraphQL is a complement/alternative to REST that allows clients to fetch or modify remote data, but with fewer round-trips. Liberty now supports the (still under development) MicroProfile GraphQL APIs (learn more) that allow developers to create GraphQL apps using simple annotations - similar to how JAX-RS uses annotations to create a RESTful app.
Developing and deploying a GraphQL app is cinch - take a look at this sample to get started with these powerful APIs!
Get Liberty 20.0.0.1 now
Available through Maven, Gradle, Docker, and as a downloadable archive.




