
In the data-driven age of AI and cloud computing, the choice between relational or NoSQL databases crucially influences a solution’s success. The Jakarta NoSQL specification addresses this challenge by providing a standard-based, easy-to-learn framework that mirrors the familiar JPA and simplifies development across various NoSQL databases. Learn about the JNopo game and delve into how Jakarta NoSQL, together with Jakarta Data, can simplify using NoSQL databases.
After getting an overview about Jakarta NoSQL, Jakarta Data, and Eclipse JNoSQL in this blog post, we’re in a good shape to explore and understand what an actual application implementation with Jakarta NoSQL would look like, through a sample game application that relies on non-relational storage and data manipulation.
Getting started: playing JNopo!
JNopo is a Java version of the famous the Rock, Paper, and Scissors game. This game consists of a battle of two players where each one chooses a move between rock, paper, or scissors. Hopefully you’re already familiar with the rules of this game, but if you are not, we’ve included some example scenarios to illustrate the game logic below. Let’s suppose that a Player A will play with a Player B and, in this case:
-
If Player A chooses ROCK and Player B chooses SCISSORS then Player A wins the game.
-
If Player A chooses PAPER and Player B chooses ROCK then Player A wins the game.
-
If Player A chooses SCISSORS and Player B chooses PAPER then Player A wins the game.
-
If Player A and Player B choose the same move, then the game is a tie and neither player wins.
In the following sequence diagram, we can illustrate the default behavior of the JNopo game:

JNopo is implemented using Jakarta EE Specifications so it’s compatible with Jakarta EE and MicroProfile runtimes. In our case, we’re using Open Liberty 23.0.0.10.
The architecture for this application is comprises two components:
-
The web page where the players interact with the game
-
The back-end where the game matches are managed
In the following image, we can see the system design of the JNopo game:
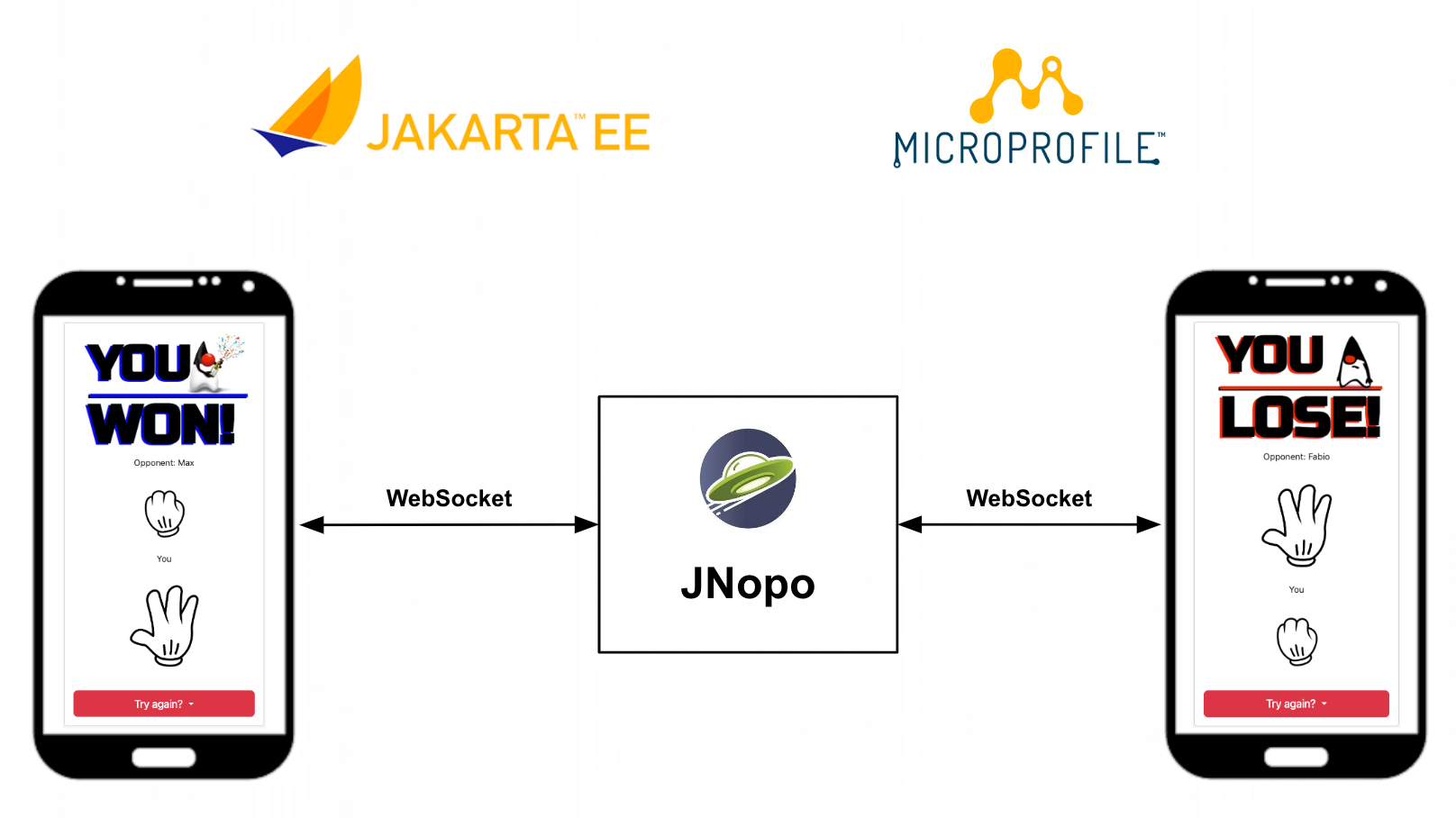
It’s fun time: Let’s play JNopo!
Before you start, this game uses the Maven Wrapper plugin, which means, you just need to have the JDK 21 or later installed in your machine to build and/or run the application.
Yeah! It’s time have fun playing JNopo!
Clone the Git repository:
git clone https://github.com/OpenLiberty/sample-jakartaNoSQL-game.git
cd sample-jakartaNoSQL-gameNavigate to the start directory. This directory contains the starting project that we’ll work through in this post.
cd startThis project is ready to run on Open Liberty. You just need to perform the following Maven Wrapper command:
-
For Mac or Linux:
./mvnw liberty:dev -
For Windows:
mvnw.cmd liberty:dev
This will install all required dependencies and start the default server.
Now, if everything works, you can play the game by accessing the following URL address:
http://localhost:9080/jakarta-nosql-game/To play the game locally you just need to open two browsers tabs/windows pointing to the same URL address.
The winner ranking challenge
This is where things get interesting: why not to challenge us to learn, create, and improve our knowledge and practical software development skills? That’s we’re going to do: let’s make JNopo provide a winner ranking!
This challenge is an amazing opportunity to learn and explore how to use Jakarta NoSQL and Jakarta Data to simplify NoSQL integration with Java applications.
To get a winner ranking, JNopo needs to persist the game matches results and then summarize the results composing the ranking. To expose this ranking, the application must provide a REST API like the following example:
curl -X GET \
-H 'Accept: application/json' \
http://localhost:9080/jakarta-nosql-game/api/playoffs/rankingThe winner ranking response is similar to the following JSON output:
{
"data" : {
"Max": 2,
"Fabio": 1
}
}As I said, it’ll be interesting!
Implementing the winner ranking
The winner ranking requires a set of game matches results. To get that, we need to add a persistence layer to JNopo that captures and stores the game match results.
Setting up the persistence layer
Let’s add the dependencies to create the persistence layer. Our persistence layer will be implemented using Jakarta NoSQL and Jakarta Data. To implement these Jakarta EE specifications, we’ll use Eclipse JNoSQL.
Eclipse JNoSQL offers a database API collection that covers document, key-value, column and graph NoSQL databases. For now, Eclipse JNoSQL supports about 30 NoSQL databases.
For this challenge, let’s develop the persistence layer to integrate with document NoSQL databases type. Eclipse JNoSQL supports various document NoSQL databases. You can find a list of supported databases, along with their configurations and dependencies, on the GitHub repository.
Configuring project dependencies
Let’s use MongoDB as the default document database. Add the following Maven dependency into the pom.xml file of the project:
<dependency>
<groupId>org.eclipse.jnosql.databases</groupId>
<artifactId>jnosql-mongodb</artifactId>
<version>1.1.0</version>
</dependency>Once you add the appropriate dependency, you need to configure the credentials for your document database. These credentials typically include details such as the database name, host, port, and any required authentication credentials. To configure MongoDB, you can find the supported credentials properties at the Eclipse JNoSQL MongoDB Database API Configuration.
Setting up local NoSQL databases
Installing and managing databases locally requires additional efforts that we will not cover it in this blog post. We chose to use Docker Compose as the tooling for managing containers locally. Take a look at the Docker Compose Overview to learn more about this tool.
Let’s create a docker-compose.yml file into the project root directory and add the following content:
services:
mongo:
image: mongo
restart: always
environment:
MONGO_INITDB_ROOT_USERNAME: root
MONGO_INITDB_ROOT_PASSWORD: example
ports:
- 27017:27017
mongo-express:
image: mongo-express:1.0.0-alpha
restart: always
ports:
- 8081:8081
environment:
ME_CONFIG_MONGODB_ADMINUSERNAME: root
ME_CONFIG_MONGODB_ADMINPASSWORD: example
ME_CONFIG_MONGODB_URL: mongodb://root:example@mongo:27017/For convenience, the previous example added a mongo-express service that allows us to navigate and manage MongoDB data through a friendly web interface.
Feel free to customize the declaration of the containers in the docker-compose.yml file. For example, the database data is saved inside the container image, which means that the data will be lost if the containers are deleted.
|
Now, to start up the databases we just need to run the following command:
docker-compose up -dYou should now be able to access the mongo-express UI at http://localhost:8081/ :
Defining database credentials
Now that we defined the MongoDB database instance, we can set up the Eclipse JNoSQL framework correctly.
Eclipse JNoSQL uses MicroProfile Config to get the required configurations to establish the connection to the databases. We can define these properties in the resources/META-INF/microprofile-config.properties file by using environment variables. For more information about MicroProfile Config, take a look at External configuration of microservices in the Open Liberty docs.
According to the docker-compose.yml file that we have created previously, we can define the following properties:
jnosql.mongodb.host=localhost:27017
jnosql.mongodb.user=root
jnosql.mongodb.password=example
jnosql.mongodb.authentication.source=adminModeling data with Jakarta NoSQL
Once we add the Eclipse JNoSQL dependencies, the Jakarta NoSQL api comes together as a transient dependency to the project, allowing us to create the NoSQL entities we want.
Let’s model the GameMatch entity, which represents each game match result.
As we said before, Eclipse JNoSQL allows us to use Java Records as entities, so, let’s use this feature:
package org.jakartaee.sample.model;
import jakarta.nosql.Column;
import jakarta.nosql.Entity;
import jakarta.nosql.Id;
@Entity
public record GameMatch (
@Id
String id,
@Column
PlayerInfo playerA,
@Column
PlayerInfo playerB,
@Column
PlayerInfo winner,
@Column
PlayerInfo loser,
@Column
Boolean tied
){
}To represent each player name and movement, let’s model such data as a PlayerInfo record class:
package org.jakartaee.sample.model;
import jakarta.nosql.Column;
import jakarta.nosql.Entity;
@Entity
public record PlayerInfo (
@Column
String name,
@Column
String movement
){
}Data store and retrieval with Jakarta Data
Now, we’ll create a component to store and retrieve such entities from the MongoDB database. It’s common to see developers using patterns like data access object (DAO) to implement these components. That’s not a problem at all, but we use to see them making the components closer to a specific vendor database semantics, raising a vendor lock-in situation.
Nowadays, in the cloud era where we pay as we go, switching between NoSQL solutions can save resources and costs. But vendor lock-in would probably compromise this strategy. Also, other considerations come to the table when there’s a need to switch databases, such as time spent on the change, the learning curve of a new API, the code that will be lost, the persistence layer that needs to be replaced, etc. This is where the flexibility of Jakarta NoSQL shines.
Another interesting point is that DAO components tend to be closer to the database semantics than the business domain model language, requiring a high cognitive load for developers to connect the dots and fill the gaps between the technical codes and business necessities, once the code is not expressive enough, and doesn’t fit with the ubiquitous language of the business. At this point, Jakarta Data comes into play!
Coming back to our challenge, let’s create a repository component that will represents the play-offs:
package org.jakartaee.sample.model;
import jakarta.data.repository.DataRepository;
import jakarta.data.repository.Query;
import jakarta.data.repository.Repository;
import jakarta.data.repository.Save;
@Repository
public interface Playoffs extends DataRepository<GameMatch,String> {
@Save
GameMatch add(GameMatch gameMatch);
}Capturing and persisting game matches
With the entity and repository already created, we need to capture and persist the results of each game match. The next obvious question is: how could we capture the required game events?
It’s a really good question! The answer is: the Events API provided by the Jakarta Context and Dependency Injection (CDI) specification!
JNopo game uses CDI Events to promote extension points, based on event publishing, to be used as needed. With that, we can implement an @Observable methods on any CDI bean to handle event objects.
See the following GameState interface. Objects that implement this interface will act as event objects:
package org.jakartaee.sample.game;
public sealed interface GameState permits
WaitingPlayers,
GameInvalid,
GameAbandoned,
GameReady,
GameRunning,
GameOver {
String gameId();
}The GameState interface is a sealed interface that defines all the supported game states. According to the sealed implementation, the event that we’re interested is the GameOver state. Such class is a record class. But it’s not just a simple record class that acts like a data transfer object (DTO), it has useful methods that return important info like:
-
The game identification
-
A tied attribute, to know whether the game ended as a tied
-
Player A and its moves
-
Player B and its moves
-
The winning player and its moves, if the game ended without a tie
-
The losing player and its moves, if the game ended without a tie
Now let`s create the GameMatchCapturer bean that captures the emitted GameOver state and stores the game match results in the database:
package org.jakartaee.sample.model;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.event.Observes;
import jakarta.inject.Inject;
import org.jakartaee.sample.game.GameOver;
@ApplicationScoped
public class GameMatchCapturer {
public void captureAndPersist(@Observes GameOver gameOver){
// put the persistence logic here...
}
}At this point, let’s instantiate a new GameMatch entity instance, populate it from GameOver data and then store it into the database by using the Playoffs component.
The required Playoff component, which is a repository implementation provided Eclipse JNoSQL, will be injected by CDI using the @Inject and @Database(DOCUMENT) annotations:
package org.jakartaee.sample.model;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.event.Observes;
import jakarta.inject.Inject;
import org.eclipse.jnosql.mapping.Database;
import org.eclipse.jnosql.mapping.DatabaseType;
import org.jakartaee.sample.game.GameOver;
@ApplicationScoped
public class GameMatchCapturer {
@Inject
@Database(DatabaseType.DOCUMENT)
Playoffs playoffs;
public void captureAndPersist(@Observes GameOver gameOver){
var gameMatch = new GameMatch(
gameOver.gameId(),
PlayerInfo.of(gameOver.playerAInfo()),
PlayerInfo.of(gameOver.playerBInfo()),
gameOver.winnerInfo().map(PlayerInfo::of).orElse(PlayerInfo.NOBODY),
gameOver.winnerInfo().map(PlayerInfo::of).orElse(PlayerInfo.NOBODY),
gameOver.isTied()
);
playoffs.add(gameMatch);
}
}Now, let’s start the Open Liberty runtime to figure out if the game match results are being stored on the MongoDB.
-
On Linux/Mac machines, run the following command:
./mvnw liberty:dev -
On Windows machines, run the following command:
mvnw.cmd liberty:dev
After some game matches, we can confirm the persistence of the game matches into the database by looking at Mongo Express running on http://localhost:8081 :
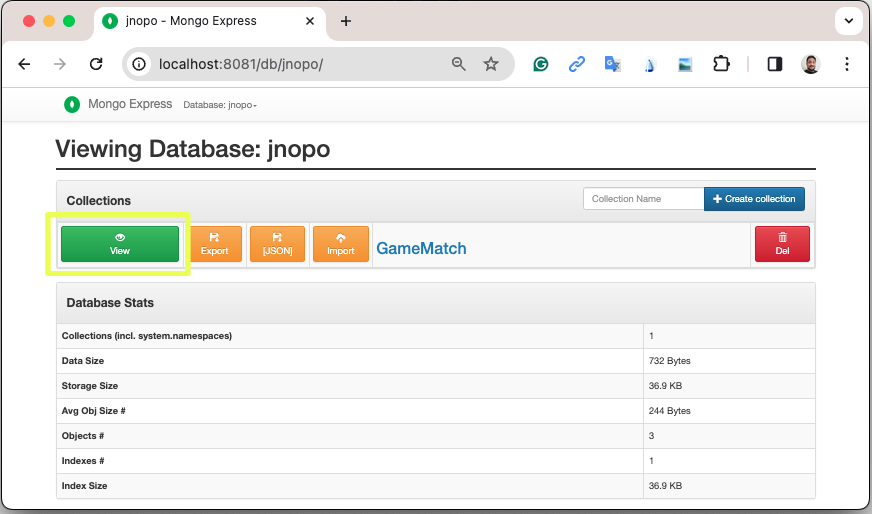
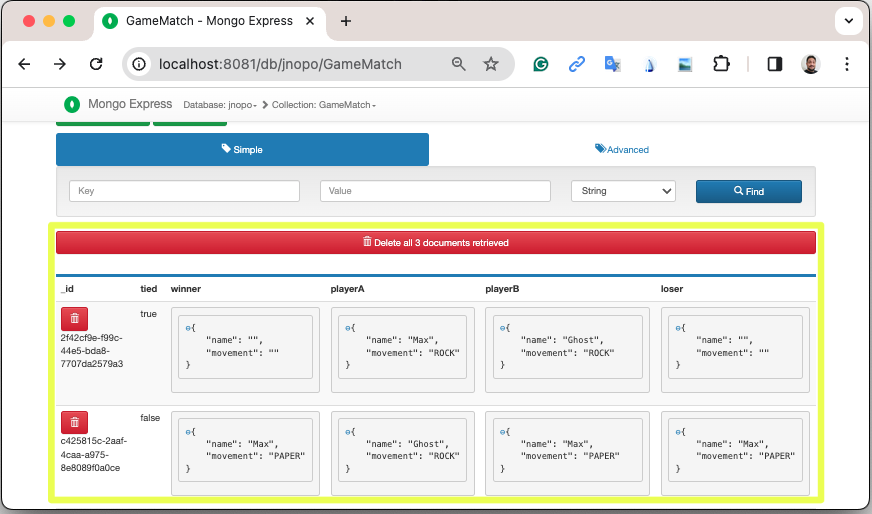
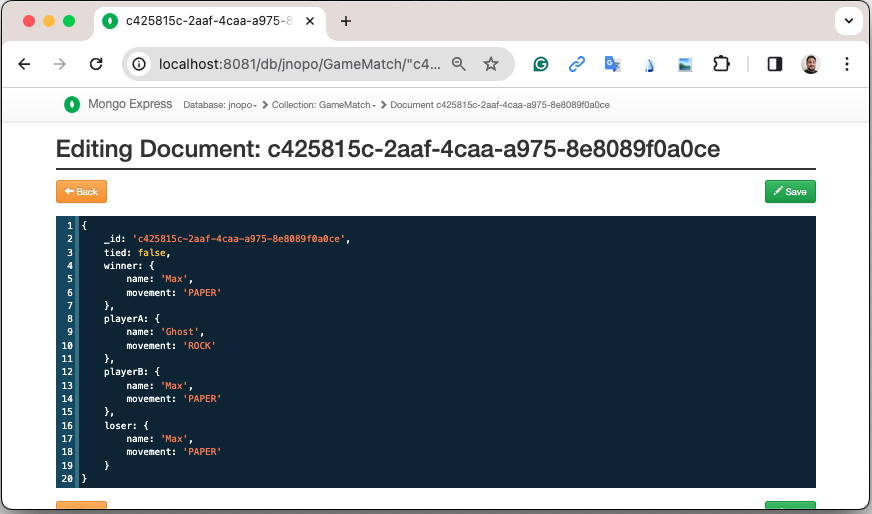
Or, if you’re a command-line practitioner, you can check the data by using the mongosh cli:
docker exec -it finish-mongo-1 mongosh -u root -p example --authenticationDatabase admin jnopoOnce connected, you can run mongo commands:
-
Getting the number of stored documents:
jnopo> db.GameMatch.countDocuments() 3 -
Getting the stored documents list:
jnopo> db.GameMatch.find() [ { _id: '2f42cf9e-f99c-44e5-bda8-7707da2579a3', tied: true, winner: { name: '', movement: '' }, playerA: { name: 'Max', movement: 'ROCK' }, playerB: { name: 'Ghost', movement: 'ROCK' }, loser: { name: '', movement: '' } }, { _id: 'c425815c-2aaf-4caa-a975-8e8089f0a0ce', tied: false, winner: { name: 'Max', movement: 'PAPER' }, playerA: { name: 'Ghost', movement: 'ROCK' }, playerB: { name: 'Max', movement: 'PAPER' }, loser: { name: 'Max', movement: 'PAPER' } }, { _id: 'bb7e7cd5-f8fe-4db1-9e90-44ecd433b4de', tied: false, winner: { name: 'Ghost', movement: 'ROCK' }, playerA: { name: 'Ghost', movement: 'ROCK' }, playerB: { name: 'Max', movement: 'SCISSORS' }, loser: { name: 'Ghost', movement: 'ROCK' } } ]
Great! JNopo is storing the game match results as expected! It’s time to create the winner ranking and then expose it though a restful endpoint: http://localhost:9080/jakarta-nosql-game/api/playoffs/ranking .
Exposing the winner ranking
Collecting and storing the game matches enables us to implement the winner ranking feature.
Let’s implement the Ranking class to represent any ranking on the JNopo application.
The Ranking creation requires the data from the Playoffs component. In order to avoid to create a new layer to keep the logic of the ranking creation, I decided to use a simple approach: a simple static factory method on the Ranking class itself.
Firstly, Playoffs needs to provide a method to retrieve the non-tied game results:
package org.jakartaee.sample.model;
import jakarta.data.repository.DataRepository;
import jakarta.data.repository.Query;
import jakarta.data.repository.Repository;
import jakarta.data.repository.Save;
import java.util.stream.Stream;
@Repository
public interface Playoffs extends DataRepository<GameMatch,String> {
@Save
GameMatch add(GameMatch gameMatch);
@Query("select * from GameMatch where tied=false")
Stream<GameMatch> nonTiedGameMatches();
}| JNoSQL offers a simple query language that is pretty similar to SQL. However, it’s not a complete SQL implementation and some aggregation and functions are not available. |
Regarding the aggregation process that evolves the ranking logic creation, we used to see developers delegating this aggregation logic to the DBMS and, depending on the persistence mechanism, it should be the best approach. For now, the grouping projection functions like we have with Jakarta Persistence is not available on the Jakarta NoSQL. However, in the future, such capabilities might be available.
In order to keep our implementation free of vendor lock-in, I decided to implement the aggregation process by using the Stream API. I added comments on the code to help you to understand the implemented logic.
package org.jakartaee.sample.model;
import java.util.Collection;
import java.util.Comparator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.stream.Collectors;
public record Ranking(Map<String, Integer> data) {
public static Ranking winnerRanking(Playoffs playoffs) {
var data =
// getting the game matches that are not tied
playoffs.nonTiedGameMatches()
// grouping by winner's name and summarize by game match
.collect(Collectors.groupingBy(
g -> g.winner().name(),
Collectors.collectingAndThen(Collectors.toList(), Collection::size)))
.entrySet()
.stream()
// sorting the results by number of game match in descending order
.sorted(Map.Entry.comparingByValue(Comparator.reverseOrder()))
// collecting as a LinkedHashMap to keep the sorted items
.collect(Collectors.toMap(
Map.Entry::getKey,
Map.Entry::getValue,
(e1, e2) -> e1, LinkedHashMap::new));
return new Ranking(data);
}
}Now, let make this ranking be accessible to our model. As the ranking needs the data from the Playoffs component, why not to put the ranking creation on the Playoffs interface? That’s we’re going to do! It is possible since the Java 8:
package org.jakartaee.sample.model;
import jakarta.data.repository.DataRepository;
import jakarta.data.repository.Query;
import jakarta.data.repository.Repository;
import jakarta.data.repository.Save;
import java.util.stream.Stream;
@Repository
public interface Playoffs extends DataRepository<GameMatch,String> {
@Save
GameMatch add(GameMatch gameMatch);
@Query("select * from GameMatch where tied=false")
Stream<GameMatch> nonTiedGameMatches();
default Ranking winnerRanking(){
return Ranking.winnerRanking(this);
}
}It looks like we’re getting closer to our goal!
Following the challenge requirements, let’s create the resource component that will expose the winner ranking.
Firstly, let’s create the RestApplication class to define the URL dedicated to restful endpoints:
package org.jakartaee.sample.resources;
import jakarta.ws.rs.ApplicationPath;
import jakarta.ws.rs.core.Application;
@ApplicationPath("/api")
public class RestApplication extends Application {
}Now, any URL under /api will be handled by the Jakarta Restful Web Services implementation available in our runtime environment.
Next step: let’s implement the PlayoffsResource resource. This component will expose an HTTP GET endpoint for the /api/playoffs/ranking URL:
package org.jakartaee.sample.resources;
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.jnosql.mapping.Database;
import org.eclipse.jnosql.mapping.DatabaseType;
import org.jakartaee.sample.model.Playoffs;
import org.jakartaee.sample.model.Ranking;
@Path("/playoffs")
@Consumes({MediaType.APPLICATION_JSON})
@Produces({MediaType.APPLICATION_JSON})
public class PlayoffsResource {
@Inject
@Database(DatabaseType.DOCUMENT)
Playoffs playoffs;
@GET
@Path("/ranking")
public Ranking getRanking() {
return playoffs.winnerRanking();
}
}It’s time to test everything! Let’s restart the Open Liberty runtime:
-
On Linux/Mac machines, run the following command:
./mvnw liberty:dev -
On Windows machines, run the following command:
mvnw.cmd liberty:dev
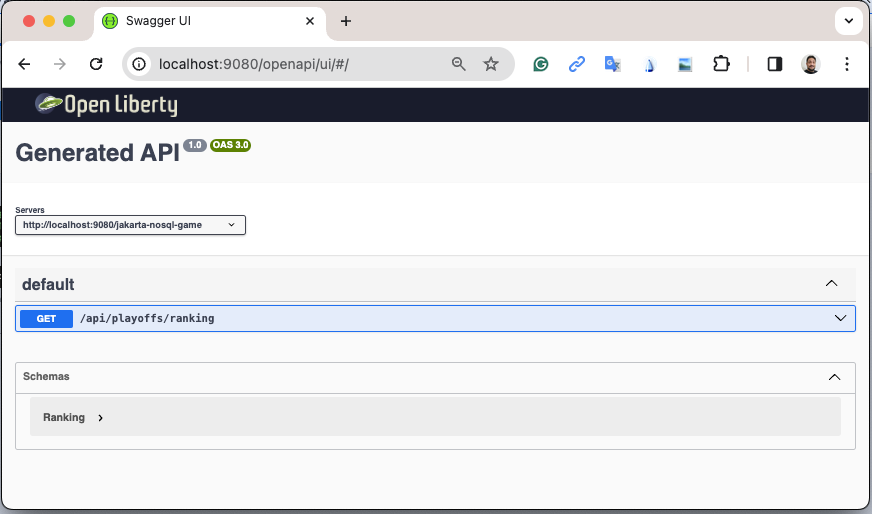
Open Liberty provides amazing tooling to help during develop Jakarta EE / MicroProfile applications. When dev mode is running, we can use some HTTP addresses to test and explore the capabilities offered by this amazing Jakarta EE/MicroProfile runtime:
[INFO] [AUDIT ] CWWKT0016I: Web application available (default_host): http://localhost:9080/openapi/
[INFO] [AUDIT ] CWWKT0016I: Web application available (default_host): http://localhost:9080/health/
[INFO] [AUDIT ] CWWKT0016I: Web application available (default_host): http://localhost:9080/jwt/
[INFO] [AUDIT ] CWWKT0016I: Web application available (default_host): http://localhost:9080/metrics/
[INFO] [AUDIT ] CWWKT0016I: Web application available (default_host): http://localhost:9080/openapi/ui/
[INFO] [AUDIT ] CWWKT0016I: Web application available (default_host): http://localhost:9080/ibm/api/
[INFO] [AUDIT ] CWWKT0016I: Web application available (default_host): http://localhost:9080/jakarta-nosql-game/Let’s focus on two of these URLs:
-
http://localhost:9080/jakarta-nosql-game/ is the URL of the application that we can use locally.
-
http://localhost:9080/openapi/ui/ is the Swagger UI interface that Open Liberty offers out-of-the-box, facilitating the rest endpoint testing via browser.
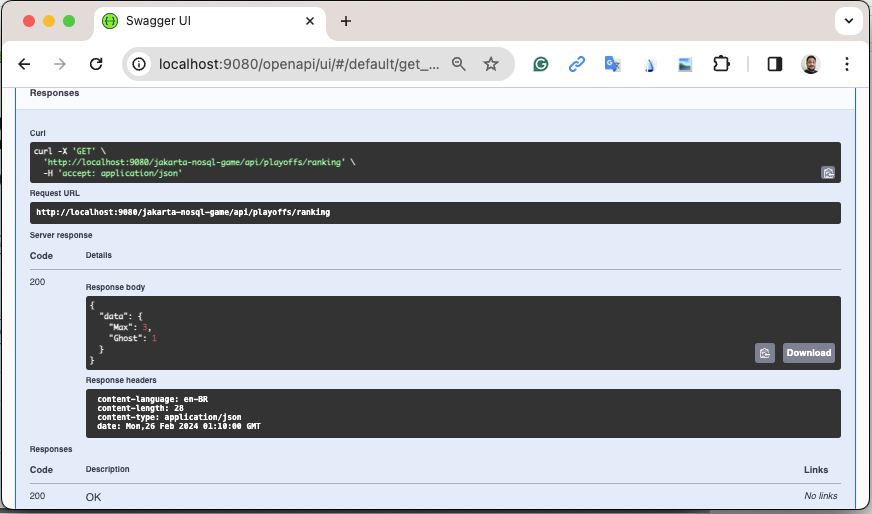
If you’re a command-line practitioner, you can check the data by using the curl command:
curl -X 'GET' \
'http://localhost:9080/jakarta-nosql-game/api/playoffs/ranking' \
-H 'accept: application/json' | jq{
"data": {
"Max": 3,
"Ghost": 1
}
}Congratulations if you made it this far!
Now, JNopo is providing a winner ranking!
If you’re interested to take a look on the finished project code version developed during this challenge, clone this Git repository and then navigate to the winner-ranking-challenge directory.
git clone https://github.com/OpenLiberty/sample-jakartaNoSQL-game.git
cd sample-jakartaNoSQL-game
cd winner-ranking-challengeKey takeaways
This challenge was an amazing opportunity to learn not just about Jakarta NoSQL and Jakarta Data to simplify the NoSQL integration with Java applications but also to explore new development approaches using interesting Java features.
What we got by doing these challenges:
-
A practical example that uses:
-
Sealed classes (final feature since Java 17)
-
Pattern Matching for Instanceof (final feature since Java 16)
-
Pattern Matching for Switch (final feature since Java 21)
-
What we learned from them:
-
How to configure Eclipse JNoSQL to allow us to work with Jakarta NoSQL and Jakarta Data in a Jakarta EE / MicroProfile project
-
How to work with Jakarta NoSQL to create entities pretty similar to Jakarta Persistence approach
-
How to create repositories with Jakarta Data, the newest Jakarta EE Specification that will be available in the Jakarta EE 11
Next steps: continuing the journey
Congratulations on getting this far!
In the next blog post, a new challenge is introduced: Switching NoSQL Databases with Ease! Stay tuned!
This blog post is the 2nd blog in a 3-part blog series. You can check out the other blogs in this series through the links below:
To see more sample projects, take a look at the official Eclipse JNoSQL samples repositories:
To learn more about Eclipse JNoSQL, take a look at these official repositories:
if you’re an expert on some NoSQL database that Eclipse JNoSQL doesn’t support, feel free to open an issue or a PR on these project repositories.
Except for the NoSQL solutions like MongoDB and Couchbase, all the technology used in this blog post is open-source, so, what do you think about contributing to these projects? If you don’t know how to get started to contribute, take a look at this Coffee.withJava("Contribute to JNoSQL") Youtube Series, or if you prefer, feel free to contact me. Contributing to these projects is not just code, you could help a lot by promoting and speaking about them wherever you go! Contributing to open-source is a great way to boost your career and improve your skills to become an effective developer and relevant in the market! Think about that!
Special thanks
I’m bursting with gratitude and would love to give a big shout-out to my incredible Java community friends for their unwavering support throughout my journey. A special round of applause for:
-
Otavio Santana, you’re not just a mentor but a guiding star in my open-source journey. Your mentorship have opened doors for me to become an active open-source contributor and a proud Eclipse Foundation committer. Thank you for being such a monumental part of my journey. Also, thanks for your insightful reviews of the codes featured in this blog post.
-
Karina Varela, your keen eye for detail and your generosity in sharing your knowledge have enriched this content beyond measure. Your thoughtful reviews have made this content not just better, but truly curated and relevant. I’m so grateful for your contribution.
-
Gabriel Silva Andrade, your support and encouragement have been a constant source of inspiration for me. Your partnership at the SouJava JUG and Java community initiatives around this subject have been invaluable in shaping this content. Thank you for your unwavering support.
-
Fabio Franco, you were the catalyst for this wonderful opportunity, connecting me with the fantastic OpenLiberty team and offering your support throughout the publishing process of this blog post. Your belief in me and your encouragement have been invaluable. Thank you for making this possible.
-
And to the OpenLiberty team, thank you for opening your doors and allowing me the privilege to share and post this content that I’ve thoroughly enjoyed working on. Thanks for this opportunity.
To each of you, your support means a lot to me, and I’m deeply thankful.
References and further reading
-
Official documentation:
-
Articles:
-
Eclipse JNoSQL 1.0.2: Empowering Java With NoSQL Database Flexibility by Otavio Santana
-
Getting Started - Accessing Oracle NoSQL Database using Jakarta NoSQL by Dario VEGA
-
Exploring the New Eclipse JNoSQL Version 1.1.0: A Dive Into Oracle NoSQL by Otavio Santana
-
Simplifying data access with MySQL and Jakarta Data by Ivar Grimstad
-
Books:




